


Semana 26: AlphaGenome, Gemini Robotics On-Device e muito mais

🧬 AlphaGenome: IA da DeepMind revoluciona a análise do genoma humano
⚖️ Justiça dos EUA dá vitória a Meta e Anthropic em processos de direitos de autor sobre treino de IA — mas com limites
🤖 Gemini Robotics On-Device: Robôs inteligentes e autónomos, sem ligação à internet
💹 Nvidia ultrapassa Microsoft e Apple como empresa mais valiosa do mundo
🧬 AlphaGenome: IA da DeepMind revoluciona a análise do genoma humano
📖 Descrição
A DeepMind lançou o AlphaGenome, um novo modelo de IA capaz de analisar sequências de ADN até 1 milhão de pares de bases e prever, com resolução ao nível de uma única base, o impacto de variantes genéticas em múltiplos processos moleculares. Esta ferramenta promete acelerar a investigação biomédica, desde a compreensão de doenças raras até ao design de ADN sintético.
🔍 Detalhes
Arquitetura híbrida (convolucional + transformer) permite captar contexto de longo alcance e detalhes finos, superando limitações de modelos anteriores como o Enformer.
Previsão simultânea de milhares de propriedades regulatórias, incluindo início/fim de genes, splicing, produção de RNA e interação com proteínas.
A DeepMind treinou todo o sistema em apenas quatro horas utilizando bases de dados genéticas públicas, consumindo metade do poder de computação do seu modelo de ADN anterior.
Supera modelos especializados em 22 de 24 benchmarks para previsão de sequências e em 24 de 26 para efeito de variantes.
Disponível via API para investigação não-comercial; lançamento público previsto.
🤔 Porque é que isto importa?
AlphaGenome representa um salto qualitativo na biologia computacional, permitindo testar hipóteses genéticas em grande escala e acelerar a descoberta de causas de doenças, potenciais terapias e avanços em biologia sintética. Ao integrar contexto genómico extenso com precisão ao nível da base, abre portas para uma compreensão mais profunda do funcionamento do genoma humano.
Fonte: AlphaGenome: AI for better understanding the genome
⚖️ Justiça dos EUA dá vitória a Meta e Anthropic em processos de direitos de autor sobre treino de IA — mas com limites

📖 Descrição
Duas decisões judiciais históricas nos EUA deram razão à Meta e à Anthropic em processos movidos por autores que alegavam uso ilegal das suas obras protegidas para treinar modelos de IA. Em ambos os casos, os juízes consideraram que, nas circunstâncias apresentadas, o treino de IA com livros protegidos por direitos de autor pode ser considerado “uso legítimo” (fair use). No entanto, as decisões sublinham que esta não é uma autorização geral para as tecnológicas e que o debate está longe de encerrado.
🔍 Detalhes
Anthropic:
O juiz William Alsup apoiou a Anthropic num caso de direitos de autor de IA, determinando que o treino - e apenas o treino - dos seus modelos de IA em livros adquiridos legalmente sem autorização dos autores é uma utilização justa.
Não foi provado que a IA (Claude) consiga gerar textos idênticos às obras originais dos autores.
A Anthropic gastou milhões na compra de livros impressos para digitalização e treino. Contudo, a empresa também descarregou 7 milhões de livros de sites piratas, o que constitui violação de direitos de autor.
Meta:
O juiz federal Vince Chhabria decidiu a favor da Meta num processo movido por 13 autores (incluindo Sarah Silverman), considerando que o treino do modelo Llama com livros protegidos se enquadra no “fair use”.
A decisão foi sumária, sem necessidade de ir a julgamento, por falta de provas de que o modelo reproduzisse ou prejudicasse o mercado das obras originais.
O tribunal comparou o treino de IA ao processo de aprendizagem de escritores humanos, considerando-o “transformativo”, mas sublinhou que casos futuros com provas mais robustas poderão ter desfechos diferentes.
🤔 Porque é que isto importa?
Estas decisões marcam um precedente importante para a indústria da IA, ao reconhecer que o treino com obras protegidas pode ser legal em certas condições — mas também alertam para os riscos de abusos e para a necessidade de legislação e jurisprudência mais clara. O resultado destes processos poderá moldar o acesso a dados para IA e o futuro dos direitos de autor na era digital, com impacto direto sobre criadores, editoras e empresas tecnológicas.
Fonte:
🤖 Gemini Robotics On-Device: Robôs inteligentes e autónomos, sem ligação à internet

📖 Descrição
A Google DeepMind apresentou o Gemini Robotics On-Device, o seu primeiro modelo de visão-linguagem-ação (VLA) capaz de funcionar inteiramente em robôs, sem necessidade de ligação à internet — mantendo um desempenho quase idêntico ao da versão cloud.
🔍 Detalhes
O modelo permite que robôs interpretem o ambiente, compreendam instruções e executem tarefas físicas complexas de forma autónoma.
Adapta-se a novos cenários com apenas 50 a 100 demonstrações, facilitando a implementação em ambientes variáveis.
Treinado inicialmente no robô ALOHA, já foi adaptado para outros tipos, incluindo humanoides e robôs bi-braço.
Inclui SDK para programadores e integração com simuladores físicos.
Outras empresas (Nvidia, Hugging Face, RLWRLD) também estão a investir em modelos fundacionais para robótica.
🤔 Porque é que isto importa?
A capacidade de operar robôs de forma autónoma e offline abre novas possibilidades para aplicações industriais, domésticas e em ambientes remotos, reduzindo a dependência da cloud e melhorando a segurança e a privacidade. A flexibilidade do Gemini Robotics On-Device pode acelerar a adoção de robôs inteligentes em múltiplos sectores.
Fonte: Gemini Robotics On-Device brings AI to local robotic devices
💹 Nvidia ultrapassa Microsoft e Apple como empresa mais valiosa do mundo

📖 Descrição
A Nvidia atingiu um valor recorde de mercado de 3,77 biliões de dólares, ultrapassando Microsoft e Apple e consolidando-se como a empresa cotada mais valiosa do planeta — impulsionada pela procura global de chips para IA.
🔍 Detalhes
Nvidia detém cerca de 90% do mercado de chips para centros de dados de IA, essenciais para gigantes como Amazon, Google, Microsoft e Meta.
Analistas preveem um valor potencial de mercado de 6 biliões de dólares.
Apesar de oscilações devido a disputas comerciais e restrições de exportação para a China, as ações subiram mais de 14% desde maio.
O CEO Jensen Huang reforçou a visão de que estamos apenas no início de uma transformação global impulsionada pela IA.
🤔 Porque é que isto importa?
O domínio da Nvidia reflete a centralidade dos chips de IA na economia digital. O crescimento explosivo da empresa é um sinal claro de que a infraestrutura de IA é agora o motor principal da inovação tecnológica e do valor bolsista.
Artigo da Semana: Reinforcement Learning Teachers of Test Time Scaling
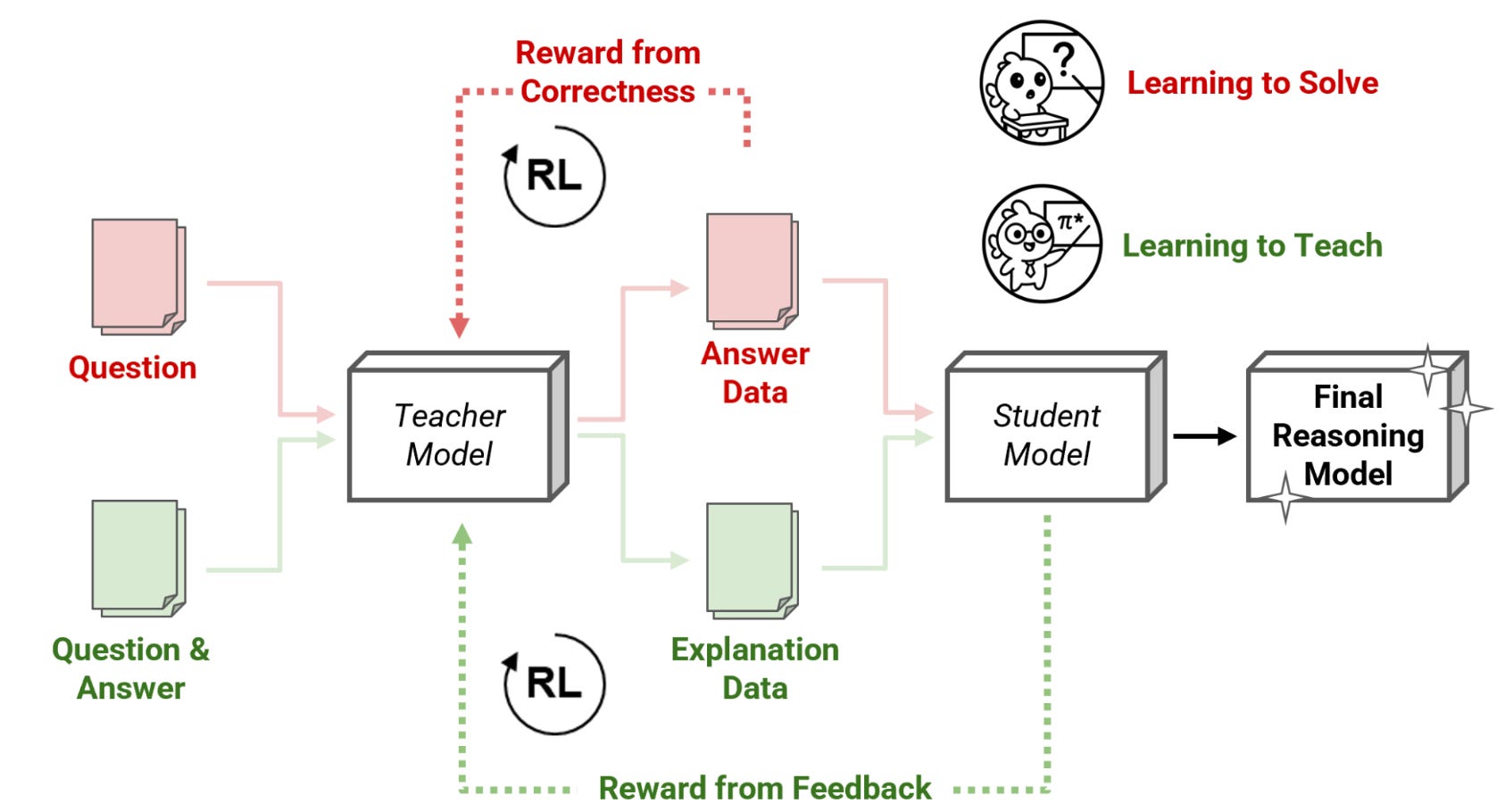
Que problema resolve?
O artigo resolve os desafios da formação tradicional de modelos de linguagem grandes (LLMs) para raciocínio, que utilizam aprendizagem por reforço (RL). Estes métodos são lentos, dispendiosos, e frequentemente levam a modelos com foco estreito e fraca capacidade de generalização. Além disso, a abordagem tradicional de "Aprender a Resolver" sofre de dois problemas principais: só é aplicável a LLMs já muito capazes e caros, e há um desalinhamento entre o objetivo de treino do professor (resolver problemas) e o seu papel real (gerar explicações claras para os alunos).
Como resolve o problema?
A solução introduz os Reinforcement-Learned Teachers (RLTs), que "aprendem a ensinar" em vez de "aprender a resolver". Durante o treino, os RLTs recebem tanto a questão como a resposta correta. O seu trabalho é gerar explicações claras e passo a passo, e são recompensados pela eficácia com que estas explicações ajudam o modelo estudante a compreender e a chegar à solução correta. Esta abordagem alinha o treino do professor com o seu verdadeiro propósito de ser útil aos alunos e permite o uso de modelos de professor pequenos e eficientes.
Quais são as principais descobertas?
Pequenos professores RLTs (com apenas 7B) superam LLMs maiores (como o DeepSeek R1 de 671B) na capacidade de ensinar raciocínio.
O método torna a formação de IA avançada mais acessível e muito mais rápida, por exemplo, treinar um estudante de 32B levou menos de um dia, em comparação com meses utilizando RL tradicional.
As explicações dos RLTs são mais focadas, claras e diretas, adicionando passos lógicos que os modelos tradicionais podem omitir, espelhando a clareza de educadores humanos.
A abordagem complementa a aprendizagem por reforço tradicional, levando a níveis de desempenho ainda mais altos quando usada como ponto de partida.
Porque é que isto importa?
Isto importa porque o framework RLT muda a forma como construímos modelos de raciocínio, tornando a IA avançada significativamente mais acessível e rápida de treinar. Permite que modelos pequenos e especializados ensinem modelos muito maiores de forma eficiente, invertendo o paradigma de escalonamento tradicional e reduzindo drasticamente os custos computacionais.
Artigo: Reinforcement Learning Teachers of Test Time Scaling